
Spring面经[下]
说一下Bean的生命周期?
在 Spring 中,Bean 的生命周期指的是 Bean 实例从创建到销毁的整个过程。Spring 容器负责管理 Bean 的生命周期,包括实例化、属性赋值、初始化、销毁等过程。
Bean 的生命周期可以分为以下几个阶段:
实例化
在 Spring 容器启动时,会根据配置文件或注解等方式创建 Bean 的实例,也就是说实例化就是为 Bean 对象分配内存空间。根据 Bean 的作用域不同,实例化的方式也不同。例如,singleton 类型的 Bean 在容器启动时就会被实例化,而 prototype 类型的 Bean 则是在每次请求时才会被实例化。
属性赋值
在 Bean 实例化后,Spring 容器会自动将配置文件或注解中指定的属性值注入到 Bean 中。属性注入可以通过构造函数注入、Setter 方法注入、注解注入等方式实现。
初始化
在属性注入完成后,Spring 容器会调用 Bean 的初始化方法。Bean 的初始化方法可以通过实现 InitializingBean 接口、@PostConstruct 注解等方式实现。在初始化方法中,可以进行一些初始化操作,例如建立数据库连接、加载配置文件等。
使用
在 Bean 初始化完成后,Bean 就可以被应用程序使用了。在应用程序中,可以通过 Spring 容器获取 Bean 的实例,并调用 Bean 的方法。
销毁
在应用程序关闭时,Spring 容器会自动销毁所有的 Bean 实例。Bean 的销毁方法可以通过实现 DisposableBean 接口、@PreDestroy 注解等方式实现。在销毁方法中,可以进行一些清理操作,例如释放资源、关闭数据库连接等。
综上所述,Spring 中的 Bean 生命周期包括实例化、属性赋值、初始化、使用和销毁等阶段。开发者可以通过实现接口或注解等方式来管理 Bean 的生命周期。
BeanFactory和FactoryBean有什么区别?
BeanFactory 和 FactoryBean 都是 Spring 框架中两个核心的概念,虽然它们都与对象创建和管理有关,但它们在功能和使用方式上存在着一些重要的区别。
BeanFactory
BeanFactory 是 Spring 框架的基本容器,负责管理和创建应用程序中的对象。它是一个工厂模式的实现,可以根据配置信息创建和管理各种类型的 Java 对象。BeanFactory 的主要职责是实例化 Bean、处理 Bean 之间的依赖关系、注入属性以及在需要时销毁 Bean。
BeanFactory 使用延迟初始化策略,即只有在请求获取 Bean 实例时才会进行实例化。这种方式可以减少资源消耗,特别是在应用程序启动时有大量的Bean需要创建时。BeanFactory 使用配置文件(如 XML)或注解来定义 Bean 和它们之间的关系。
BeanFactory 简单实现代码如下:
// 得到 BeanFactory 对象
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("spring-config.xml"));
// 使用 BeanFactory 得到 User 对象
beanFactory.getBean("user");FactoryBean
FactoryBean 是一个特殊的 Bean,它实现了 Spring 的 FactoryBean 接口。与普通的 Bean 不同,FactoryBean 负责创建其他 Bean 实例。它是一种更加灵活和可扩展的机制,可以通过编程的方式动态地创建和配置Bean。
FactoryBean 接口定义了三个方法:getObject()、getObjectType() 和 isSingleton()。getObject() 方法返回由 FactoryBean 创建的 Bean 实例,getObjectType() 方法返回创建的Bean的类型,而 isSingleton() 方法用于指示创建的 Bean 是否是单例。
FactoryBean 的实现类可以自定义创建和管理 Bean 的逻辑。例如,它可以根据条件选择性地创建不同的实例,或者在创建 Bean 之前进行一些初始化操作。FactoryBean 通常在 Spring 配置文件中配置,并由 BeanFactory 负责实例化和管理。
FactoryBean 简单示例如下:
import org.springframework.beans.factory.FactoryBean;
public class MyBeanFactory implements FactoryBean<MyBean> {
@Override
public MyBean getObject() throws Exception {
// 在这里定义创建 Bean 的逻辑
MyBean myBean = new MyBean();
// 进行一些初始化操作
myBean.setName("Example Bean");
// 返回创建的 Bean 实例
return myBean;
}
@Override
public Class<?> getObjectType() {
// 返回创建的 Bean 的类型
return MyBean.class;
}
@Override
public boolean isSingleton() {
// 指示创建的 Bean 是否是单例
return true;
}
}在上面的示例中,我们创建了一个名为 MyBeanFactory 的类,它实现了 FactoryBean 接口。在 getObject() 方法中,我们定义了创建 MyBean 实例的逻辑,并在此处进行了一些初始化操作。getObjectType() 方法返回了我们要创建的 Bean 的类型,即 MyBean.class。最后,我们通过 isSingleton() 方法指示创建的 Bean 是单例还是多例。
之后,我们需要在 Spring 配置文件中,我们可以将 MyBeanFactory 配置为一个 Bean,并使用它来创建我们需要的 Bean 实例。示例配置如下:
<bean id="myBeanFactory" class="com.example.MyBeanFactory"/>
<bean id="myBean" factory-bean="myBeanFactory" factory-method="getObject"/>在上述配置中,我们首先定义了一个名为 myBeanFactory 的 Bean,它是我们实现的 MyBeanFactory 类的实例。接下来,我们使用 factory-bean 属性指定 myBeanFactory 作为工厂 Bean,并使用 factory-method 属性指定 getObject 方法来创建我们需要的 Bean 实例,即 myBean 类。
区别
BeanFactory 是 Spring 的基本容器,用于创建和管理 Bean 实例,而 FactoryBean 是一个特殊的 Bean,用于创建其他 Bean 实例。
下面是 BeanFactory 和 FactoryBean 之间的一些关键区别:
- 功能:BeanFactory 是一个容器,负责管理和创建 Bean 实例,处理依赖关系和属性注入等操作。FactoryBean 是一个接口,定义了创建 Bean 的规范和逻辑,它负责创建其他 Bean 实例。
- 使用方式:BeanFactory 使用配置文件或注解来定义 Bean 和它们之间的关系,它使用延迟初始化策略,即只有在需要时才创建 Bean 实例。FactoryBean 通常在 Spring 配置文件中配置,并由 BeanFactory 负责实例化和管理。
- 创建的对象:BeanFactory 创建和管理普通的 Bean 实例,而 FactoryBean 创建其他 Bean 实例。
- 灵活性:FactoryBean 具有更高的灵活性,因为它允许自定义的逻辑来创建和配置 Bean 实例。FactoryBean 的实现类可以根据特定的条件选择性地创建不同的 Bean 实例,或者在创建 Bean 之前进行一些初始化操作。这使得 FactoryBean 在某些情况下比 BeanFactory 更加强大和可扩展。
- 返回类型:BeanFactory 返回的是 Bean 实例本身,而 FactoryBean 返回的是由 FactoryBean 创建的 Bean 实例。因此,当使用 FactoryBean 时,需要通过调用 getObject() 方法来获取创建的 Bean 实例。
小结
BeanFactory 和 FactoryBean 是 Spring 框架中的两个关键概念,用于创建和管理 Bean 实例。BeanFactory 是 Spring 的基本容器,负责创建和管理 Bean 实例的,而 FactoryBean 是一个特殊的 Bean,它实现了 FactoryBean 接口,负责创建其他 Bean 实例,并提供一些初始化 Bean 的设置。
Spring中使用了哪些设计模式?
工厂模式
工厂模式是一种创建型设计模式,它提供了一种创建对象的方式,使得应用程序可以更加灵活和可维护。在 Spring 中,FactoryBean 就是一个工厂模式的实现,使用它的工厂模式就可以创建出来其他的 Bean 对象。
单例模式
单例模式是一种创建型设计模式,它保证一个类只有一个实例,并提供了一个全局访问点。在 Spring 中,Bean 默认是单例的,这意味着每个 Bean 只会被创建一次,并且可以在整个应用程序中共享。
代理模式
代理模式是一种结构型设计模式,它允许开发人员在不修改原有代码的情况下,向应用程序中添加新的功能。在 Spring AOP(面向切面编程)就是使用代理模式的实现,它允许开发人员在方法调用前后执行一些自定义的操作,比如日志记录、性能监控等。
观察者模式
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。Spring 事件驱动模型使用观察者模式,ApplicationEventPublisher 事件发布者将事件发布给 ApplicationEventMulticaster 事件广播器,该广播器将事件派发给 @EventListener 注解的事件监听者。
模版方法模式
模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。在 Spring 中,JdbcTemplate 就是一个模板方法模式的实现,它提供了一种简单的方式来执行 SQL 查询和更新操作。
适配器模式
适配器模式是一种结构型设计模式,它允许开发人员将一个类的接口转换成另一个类的接口,以满足客户端的需求。在 Spring 中,适配器模式常用于将不同类型的对象转换成统一的接口,比如将 Servlet API 转换成 Spring MVC 的控制器接口。
策略模式
策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使得它们可以互相替换。Spring 中的 TaskExecutor,TaskExecutor 提供了很多实现,比如以下这些:
- SyncTaskExecutor:直接在调用线程中执行任务,没有真正的异步;
- SimpleAsyncTaskExecutor:使用单线程池异步执行任务;
- ConcurrentTaskExecutor:使用线程池异步执行任务;
- SimpleTransactionalTaskExecutor:支持事务的 SimpleAsyncTaskExecutor。 这样,我们可以根据自己的需求选择不同的实现策略,使用策略模式的好处有以下这些:
- 可以在不修改原代码的基础上选择不同的算法或策略;
- 可减少程序中的条件语句,根据环境改变选择合适的策略;
- 扩展性好,如果有新的策略出现,只需要创建一个新的策略类,无须修改原代码。
Spring和SpringBoot有什么区别?
Spring 和 Spring Boot 都是 Java 开发中非常流行的框架,它们都可以用于构建企业级应用程序。虽然它们都是 Spring 框架的一部分,但是它们之间还是有一些区别的。
Spring
Spring 是一个轻量级的开源框架,它提供了一种简单的方式来构建企业级应用程序。Spring 框架的核心是 IoC(Inversion of Control)和 AOP(Aspect Oriented Programming)两个概念。
IoC 是一种设计模式,它将对象的创建和依赖关系的管理从应用程序代码中分离出来,使得应用程序更加灵活和可维护。
AOP 是一种编程范式,它允许开发人员在不修改原有代码的情况下,向应用程序中添加新的功能。
Spring 框架提供了很多模块,包括核心容器、数据访问、Web、AOP、消息、测试等。开发人员可以根据自己的需求选择合适的模块来构建应用程序。
SpringBoot
Spring Boot 本质上是 Spring 框架的延伸和扩展,它的诞生是为了简化 Spring 框架初始搭建以及开发的过程,使用它可以不再依赖 Spring 应用程序中的 XML 配置,为更快、更高效的开发 Spring 提供更加有力的支持。 Spring Boot 也提供了很多特性,包括自动配置、嵌入式 Web 服务器、健康检查、度量指标、安全性等。开发人员可以通过使用 Spring Boot Starter 来快速集成常用的第三方库和框架,比如 Spring Data、Spring Security、MyBatis、Redis 等。
小结
Spring 和 Spring Boot 的区别在于它们的目标和用途不同。Spring 是一个轻量级的开源框架,它提供了一种简单的方式来构建企业级应用程序。Spring Boot 则是 Spring 框架的延伸和扩展,它提供了一种快速构建应用程序的方式。开发人员可以通过使用 Spring Boot Starter 来快速集成常用的第三方库和框架,使得开发人员可以快速构建出一个可运行的应用程序。
SpringBoot有哪些优点?
Spring Boot 是一个基于 Spring 框架的快速开发框架,它有以下优点:
- 简化配置: Spring Boot 采用约定大于配置的原则,提供了自动配置的特性,大部分情况下无需手动配置,可以快速启动和运行应用程序。同时,Spring Boot 提供了统一的配置模型,集成了大量常用的第三方库和框架,简化了配置过程。
- 内嵌服务器: Spring Boot 集成了常用的内嵌式服务器,如 Tomcat、Jetty 和 Undertow 等。这意味着不再需要单独安装和配置外部服务器,可以直接运行 Spring Boot 应用程序,简化了部署和发布过程。
- 自动装配: Spring Boot 提供了自动装配机制,根据应用程序的依赖关系和配置信息,智能地自动配置 Spring 的各种组件和功能,大大减少了开发人员的手动配置工作,提高了开发效率。
- 起步依赖: Spring Boot 引入了起步依赖(Starter Dependencies)的概念,它是一种可用于快速集成相关技术栈的依赖项集合。起步依赖能够自动处理依赖冲突和版本兼容性,并提供了默认的配置和依赖管理,简化了构建和管理项目的过程。
- 自动化监控和管理: Spring Boot 集成了 Actuator 模块,提供了对应用程序的自动化监控、管理和运维支持。通过 Actuator,可以获取应用程序的健康状况、性能指标、配置信息等,方便运维人员进行故障排查和性能优化。
- 丰富的生态系统: Spring Boot 建立在 Spring Framework 的基础上,可以无缝集成 Spring 的各种功能和扩展,如 Spring Data、Spring Security、Spring Integration 等。同时,Spring Boot 还提供了大量的第三方库和插件,可以方便地集成其他技术栈,构建全栈式应用程序。
- 可扩展性和灵活性: 尽管 Spring Boot 提供了很多自动化的功能和约定,但它也保持了良好的可扩展性和灵活性。开发人员可以根据自己的需求进行自定义配置和扩展,以满足特定的业务需求。
综上所述,Spring Boot 是一个强大而又灵活的开发框架,具有简化配置、快速开发、自动化监控、微服务支持等诸多优点。它极大地提高了开发效率、降低了开发成本,并且在行业中得到了广泛的认可和应用。
什么是SpringBoot自动装配?
Spring Boot 的自动装配(Auto-configuration)是 Spring Boot 框架的核心特性之一。通过自动装配可以自动配置和加载 Spring Boot 所需的各种组件和功能,从而大大的减少开发人员手动配置的工作。
在传统的 Spring 应用程序中,我们需要手动配置各种组件,如数据源、Web 容器、事务管理器等。这些配置需要编写大量的 XML 配置文件或 Java 配置类,增加了开发的工作量和复杂性。而 Spring Boot 的自动装配通过约定大于配置的原则,根据项目的依赖和配置信息,自动进行配置,使得开发人员无需进行大量的手动配置。
自动装配工作原理
Spring Boot 在启动时,会检索所有的 Spring 模块,找到符合条件的配置并应用到应用上下文中。这个过程发生在 SpringApplication 这个类中。
Spring Boot 自动装配主要依靠两部分:
- SpringFactoriesLoader 驱动:在启动过程中会加载 META-INF/spring.factories 配置文件,获取自动装配相关的配置类信息。
- 条件装配:Spring Boot 不会永远都自动装配,它会根据类路径下是否存在某个名称符合命名规则的自动装配类来决定是否进行自动装配。这就是条件装配,通过 @Conditional 条件注解完成。
自动装配流程
Spring Boot 自动装配执行流程如下:
- Spring Boot 启动时会创建一个 SpringApplication 实例,该实例存储了应用相关信息,它负责启动并运行应用。
- 实例化 SpringApplication 时,会自动装载 META-INF/spring.factories 中配置的自动装配类。
- SpringApplication 实例调用 run() 方法启动应用。
- 在 run() 方法中,实例会创建默认的应用上下文 Environment 以及 ApplicationContext。
- SpringApplication 会通过 ListableBeanFactory 加载应用上下文 ApplicationContext 中的所有 BeanDefinition。
- 在 BeanDefinition 加载过程中,SpringApplication 会检测是否存在基于 @Conditional 条件装配注解的自动装配类。
- 如果存在且 @Conditional 条件校验成功,则会装配这些自动装配类。
- 这些自动装配类通过 @EnableAutoConfiguration、@Configuration 等注解,装配默认的 Spring Bean。
- 装配完成后,Spring Boot 将启动应用,这里会启动嵌入的 Web 服务器,如 Tomcat 并发布 Web 应用。
- 发布完成,Spring Boot 应用启动成功。
自动装配是 Spring Boot 框架中的一个重要特性,它可以帮助开发人员更加方便地使用 Spring Boot 框架,提高开发效率,保证应用程序的正确性和稳定性。
SpringBoot中如何实现缓存预热?
缓存预热是指在 Spring Boot 项目启动时,预先将数据加载到缓存系统(如 Redis)中的一种机制。
那么问题来了,在 Spring Boot 项目启动之后,在什么时候?在哪里可以将数据加载到缓存系统呢?
实现方案概述
在 Spring Boot 启动之后,可以通过以下手段实现缓存预热:
- 使用启动监听事件实现缓存预热。
- 使用 @PostConstruct 注解实现缓存预热。
- 使用 CommandLineRunner 或 ApplicationRunner 实现缓存预热。
- 通过实现 InitializingBean 接口,并重写 afterPropertiesSet 方法实现缓存预热。
具体实现方案
启动监听事件
可以使用 ApplicationListener 监听 ContextRefreshedEvent 或 ApplicationReadyEvent 等应用上下文初始化完成事件,在这些事件触发后执行数据加载到缓存的操作,具体实现如下:
@Component
public class CacheWarmer implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}或监听 ApplicationReadyEvent 事件,如下代码所示:
@Component
public class CacheWarmer implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}@PostConstruct
在需要进行缓存预热的类上添加 @Component 注解,并在其方法中添加 @PostConstruct 注解和缓存预热的业务逻辑,具体实现代码如下:
@Component
public class CachePreloader {
@Autowired
private YourCacheManager cacheManager;
@PostConstruct
public void preloadCache() {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}在Java EE规范中,@PostConstruct注解被定义为一个元注解,它被用于标记一个方法,该方法将在bean的依赖注入完成之后被调用。该方法没有参数,返回值类型可以是void或任意其他类型。
@PostConstruct注解的实现可以追溯到Java EE规范中的javax.annotation包。具体而言,@PostConstruct注解的定义位于javax.annotation包中的javax.annotation.PostConstruct接口中。该接口只有一个方法,即void postConstruct()。
在Java EE容器中,当一个bean被创建并且所有的依赖注入完成之后,容器将检查该bean是否使用了@PostConstruct注解。如果是,容器将调用该bean中标记了@PostConstruct注解的方法。
init()方法是Spring容器初始化的核心方法,它会扫描所有的bean定义,并调用所有的构造函数、初始化方法、@PostConstruct注解的方法。在这个方法中,Spring容器会先获取所有的bean定义,然后依次对每个bean定义进行初始化。
在初始化每个bean定义时,Spring容器会先获取所有的构造函数,并初始化bean实例。在初始化bean实例时,Spring容器会调用所有的初始化方法和@PostConstruct注解的方法。如果初始化方法或@PostConstruct注解的方法有参数,则会通过反射机制调用它们,并传入参数。
需要注意的是,如果一个bean定义没有构造函数或初始化方法,并且也没有标有@PostConstruct注解,则该bean定义不会被初始化。
@PostConstruct注意事项
1.@PostConstruct注解的方法不能有参数,且必须是非静态的。
2.@PostConstruct注解的方法可以有任何访问修饰符,比如public,private等。
3.如果一个类中存在多个@PostConstruct注解的方法,这些方法的执行顺序是不确定的。
4.如果在一个bean类中同时使用了@Autowired和@PostConstruct注解,那么@Autowired注解的方法会在@PostConstruct注解的方法之前执行。
5.@PostConstruct注解的方法不能在非单例的Bean上使用。因为非单例bean在初始化时,在一个线程中,容易出现线程安全问题。
CommandLineRunner或ApplicationRunner
CommandLineRunner 和 ApplicationRunner 都是 Spring Boot 应用程序启动后要执行的接口,它们都允许我们在应用启动后执行一些自定义的初始化逻辑,例如缓存预热。 CommandLineRunner 实现示例如下:
@Component
public class MyCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}@Component
public class MyApplicationRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}CommandLineRunner 和 ApplicationRunner 区别如下:
方法签名不同:
- CommandLineRunner 接口有一个 run(String... args) 方法,它接收命令行参数作为可变长度字符串数组。
- ApplicationRunner 接口则提供了一个 run(ApplicationArguments args) 方法,它接收一个 ApplicationArguments 对象作为参数,这个对象提供了对传入的所有命令行参数(包括选项和非选项参数)的访问。
参数解析方式不同:
- CommandLineRunner 接口更简单直接,适合处理简单的命令行参数。
- ApplicationRunner 接口提供了一种更强大的参数解析能力,可以通过 ApplicationArguments 获取详细的参数信息,比如获取选项参数及其值、非选项参数列表以及查询是否存在特定参数等。
使用场景不同:
- 当只需要处理一组简单的命令行参数时,可以使用 CommandLineRunner。
- 对于需要精细控制和解析命令行参数的复杂场景,推荐使用 ApplicationRunner。
实现InitializingBean接口
实现 InitializingBean 接口并重写 afterPropertiesSet 方法,可以在 Spring Bean 初始化完成后执行缓存预热,具体实现代码如下:
@Component
public class CachePreloader implements InitializingBean {
@Autowired
private YourCacheManager cacheManager;
@Override
public void afterPropertiesSet() throws Exception {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}缓存预热是指在 Spring Boot 项目启动时,预先将数据加载到缓存系统(如 Redis)中的一种机制。它可以通过监听 ContextRefreshedEvent 或 ApplicationReadyEvent 启动事件,或使用 @PostConstruct 注解,或实现 CommandLineRunner 接口、ApplicationRunner 接口,和 InitializingBean 接口的方式来完成。
有几种获取Request对象的方法
HttpServletRequest 简称 Request,它是一个 Servlet API 提供的对象,用于获取客户端发起的 HTTP 请求信息。例如:获取请求参数、获取请求头、获取 Session 会话信息、获取请求的 IP 地址等信息。
那么问题来了,在 Spring Boot 中,获取 Request 对象的方法有哪些?
常见的获取 Request 对象的方法有以下三种:
- 通过请求参数中获取 Request 对象;
- 通过 RequestContextHolder 获取 Request 对象;
- 通过自动注入获取 Request 对象。
具体实现如下。
通过请求参数获取
实现代码:
@RequestMapping("/index")
@ResponseBody
public void index(HttpServletRequest request){
// do something
}该方法实现的原理是 Controller 开始处理请求时,Spring 会将 Request 对象赋值到方法参数中,我们直接设置到参数中即可得到 Request 对象。
通过 RequestContextHolder 获取
在 Spring Boot 中,RequestContextHolder 是 Spring 框架提供的一个工具类,用于在多线程环境中存储和访问与当前线程相关的请求上下文信息。它主要用于将当前请求的信息存储在线程范围内,以便在不同的组件中共享和访问这些信息,特别是在没有直接传递参数的情况下。 RequestContextHolder 的主要作用有以下几个:
- 访问请求上下文信息: 在 Web 应用中,每个请求都会触发一个新的线程来处理。RequestContextHolder 允许你在任何地方获取当前请求的上下文信息,比如 HttpServletRequest 对象、会话信息等。
- 跨层传递信息: 在多层架构中,比如控制器、服务层、数据访问层,你可能需要在这些层之间传递一些与请求相关的信息,但不想在每个方法中显式传递。通过 RequestContextHolder,你可以在一处设置请求信息,在其他地方获取并使用。
- 线程安全的上下文共享: RequestContextHolder 使用线程局部变量来存储请求上下文信息,确保在多线程环境下每个线程访问的上下文信息都是独立的,避免了线程安全问题。
因此我们可以使用 RequestContextHolde 获取 Request 对象,实现代码如下:
@RequestMapping("/index")
@ResponseBody
public void index(){
ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes();
HttpServletRequest request = servletRequestAttributes.getRequest();
// do something
}通过自动注入获取
ttpServletRequest 对象也可以通过自动注入,如属性注入的方式获取,如下代码所示:
@Controller
public class HomeController{
@Autowired
private HttpServletRequest request; // 自动注入 request 对象
// do something
}Request 对象是获取客户端 HTTP 请求的重要对象,也是 Spring Boot 的重要对象之一,获取此对象的常用方法有:通过请求参数获取、通过 RequestContextHolder 获取,以及通过注入获取。
如何实现拦截器?
在 Spring Boot 中拦截器的实现分为两步:
- 创建一个普通的拦截器,实现 HandlerInterceptor 接口,并重写接口中的相关方法;
- 将上一步创建的拦截器加入到 Spring Boot 的配置文件中,并配置拦截规则。
具体实现如下。
自定义拦截器
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component
public class TestInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截器:执行 preHandle 方法。");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("拦截器:执行 postHandle 方法。");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("拦截器:执行 afterCompletion 方法。");
}
}其中:
- boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handle):在请求方法执行前被调用,也就是调用目标方法之前被调用。比如我们在操作数据之前先要验证用户的登录信息,就可以在此方法中实现,如果验证成功则返回 true,继续执行数据操作业务;否则就返回 false,后续操作数据的业务就不会被执行了。
- void postHandle(HttpServletRequest request, HttpServletResponse response, Object handle, ModelAndView modelAndView):调用请求方法之后执行,但它会在 DispatcherServlet 进行渲染视图之前被执行。
- void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handle, Exception ex):会在整个请求结束之后再执行,也就是在 DispatcherServlet 渲染了对应的视图之后再执行。
配置拦截器规则
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class AppConfig implements WebMvcConfigurer {
// 注入拦截器
@Autowired
private TestInterceptor testInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(testInterceptor) // 添加拦截器
.addPathPatterns("/**"); // 拦截所有地址
.excludePathPatterns("/login"); // 放行接口
}
}如何实现过滤器?
过滤器可以使用 Servlet 3.0 提供的 @WebFilter 注解,配置过滤的 URL 规则,然后再实现 Filter 接口,重写接口中的 doFilter 方法,具体实现代码如下:
import org.springframework.stereotype.Component;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@Component
@WebFilter(urlPatterns = "/*")
public class TestFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("过滤器:执行 init 方法。");
}
@Override
public void doFilter(ServletRequest servletRequest,
ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
System.out.println("过滤器:开始执行 doFilter 方法。");
// 请求放行
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("过滤器:结束执行 doFilter 方法。");
}
@Override
public void destroy() {
System.out.println("过滤器:执行 destroy 方法。");
}
}其中:
- void init(FilterConfig filterConfig):容器启动(初始化 Filter)时会被调用,整个程序运行期只会被调用一次。用于实现 Filter 对象的初始化。
- void doFilter(ServletRequest request, ServletResponse response,FilterChain chain):具体的过滤功能实现代码,通过此方法对请求进行过滤处理,其中 FilterChain 参数是用来调用下一个过滤器或执行下一个流程。
- void destroy():用于 Filter 销毁前完成相关资源的回收工作
拦截器和过滤器有什么区别?
拦截器和过滤器的区别主要体现在以下 5 点:
- 出身不同:过滤器来自于 Servlet,而拦截器来自于 Spring 框架;
- 触发时机不同:请求的执行顺序是:请求进入容器 > 进入过滤器 > 进入 Servlet > 进入拦截器 > 执行控制器(Controller),所以过滤器和拦截器的执行时机,是过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法;
- 底层实现不同:过滤器是基于方法回调实现的,拦截器是基于动态代理(底层是反射)实现的;
- 支持的项目类型不同:过滤器是 Servlet 规范中定义的,所以过滤器要依赖 Servlet 容器,它只能用在 Web 项目中;而拦截器是 Spring 中的一个组件,因此拦截器既可以用在 Web 项目中,同时还可以用在 Application 或 Swing 程序中;
- 使用的场景不同:因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:登录判断、权限判断、日志记录等业务;而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、字符集编码设置、响应数据压缩等功能。
拦截器和动态代理有什么区别?
拦截器实现原理
Spring Boot 拦截器是基于 Java 的 Servlet 规范实现的,通过实现 HandlerInterceptor 接口来实现拦截器功能。
在 Spring Boot 框架的执行流程中,拦截器被注册在 DispatcherServlet 的 doDispatch() 方法中,该方法是 Spring Boot 框架的核心方法,用于处理请求和响应。
程序每次执行时都会调用 doDispatch() 方法时,并验证拦截器(链),之后再根据拦截器返回的结果,进行下一步的处理。如果返回的是 true,那么继续调用目标方法,反之则会直接返回验证失败给前端。
doDispatch 源码实现如下:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
try {
ModelAndView mv = null;
Object dispatchException = null;
try {
processedRequest = this.checkMultipart(request);
multipartRequestParsed = processedRequest != request;
mappedHandler = this.getHandler(processedRequest);
if (mappedHandler == null) {
this.noHandlerFound(processedRequest, response);
return;
}
HandlerAdapter ha = this.getHandlerAdapter(mappedHandler.getHandler());
String method = request.getMethod();
boolean isGet = HttpMethod.GET.matches(method);
if (isGet || HttpMethod.HEAD.matches(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if ((new ServletWebRequest(request, response)).checkNotModified(lastModified) && isGet) {
return;
}
}
// 调用预处理【重点】
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
// 执行 Controller 中的业务
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
this.applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
} catch (Exception var20) {
dispatchException = var20;
} catch (Throwable var21) {
dispatchException = new NestedServletException("Handler dispatch failed", var21);
}
this.processDispatchResult(processedRequest, response, mappedHandler, mv, (Exception)dispatchException);
} catch (Exception var22) {
this.triggerAfterCompletion(processedRequest, response, mappedHandler, var22);
} catch (Throwable var23) {
this.triggerAfterCompletion(processedRequest, response, mappedHandler, new NestedServletException("Handler processing failed", var23));
}
} finally {
if (asyncManager.isConcurrentHandlingStarted()) {
if (mappedHandler != null) {
mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
}
} else if (multipartRequestParsed) {
this.cleanupMultipart(processedRequest);
}
}
}从上述源码可以看出在开始执行 Controller 之前,会先调用 预处理方法 applyPreHandle,而 applyPreHandle 方法的实现源码如下:
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
for(int i = 0; i < this.interceptorList.size(); this.interceptorIndex = i++) {
// 获取项目中使用的拦截器 HandlerInterceptor
HandlerInterceptor interceptor = (HandlerInterceptor)this.interceptorList.get(i);
if (!interceptor.preHandle(request, response, this.handler)) {
this.triggerAfterCompletion(request, response, (Exception)null);
return false;
}
}
return true;
}从上述源码可以看出,在 applyPreHandle 中会获取所有的拦截器 HandlerInterceptor 并执行拦截器中的 preHandle 方法,这样就会咱们前面定义的拦截器对应上了,如下图所示:

此时用户登录权限的验证方法就会执行,这就是拦截器的执行过程。 因此,可以得出结论,拦截器的实现主要是依赖 Servlet 或 Spring 执行流程来进行拦截和功能增强的。
动态代理原理
动态代理是一种设计模式,它是指在运行时提供代理对象,来扩展目标对象的功能。 在 Spring 中的,动态代理的实现手段有以下两种:
- JDK 动态代理:通过反射机制生成代理对象,目标对象必须实现接口。
- CGLIB 动态代理:通过生成目标类的子类来实现代理,不要求目标对象实现接口。
动态代理的主要作用包括:
- 扩展目标对象的功能:如添加日志、验证参数等。
- 控制目标对象的访问:如进行权限控制。
- 延迟加载目标对象:在需要时才实例化目标对象。
- 远程代理:将请求转发到远程的目标对象上。
区别
因此,我们可以得出结论,拦截器和动态代理虽然都是用来实现功能增强的,但二者完全不同,他们的主要区别体现在以下几点:
- 使用范围不同:拦截器通常用于 Spring MVC 中,主要用于拦截 Controller 请求。动态代理可以使用在 Bean 中,主要用于提供 bean 的代理对象,实现对 bean 方法的拦截。
- 实现原理不同:拦截器是通过 HandlerInterceptor 接口来实现的,主要是通过 afterCompletion、postHandle、preHandle 这三个方法在请求前后进行拦截处理。动态代理主要有 JDK 动态代理和 CGLIB 动态代理,JDK 通过反射生成代理类;CGLIB 通过生成被代理类的子类来实现代理。
- 加入时机不同:拦截器是在运行阶段动态加入的;动态代理是在编译期或运行期生成的代理类。
- 使用难易程度不同:拦截器相对简单,通过实现接口即可使用。动态代理稍微复杂,需要了解动态代理的实现原理,然后通过相应的 api 实现。
实际工作中哪些地方用到了自定义注解?
自定义注解可以标记在方法上或类上,用于在编译期或运行期进行特定的业务功能处理。在 Java 中,自定义注解使用 @interface 关键字来定义,它可以实现如:日志记录、性能监控、权限校验等功能。
在 Spring Boot 中实现一个自定义注解,可以通过 AOP(面向切面编程)或拦截器(Interceptor)来实现。
实现自定义注解
下面我们先使用 AOP 的方式来实现一个打印日志的自定义注解,它的实现步骤如下:
- 添加 Spring AOP 依赖。
- 创建自定义注解。
- 编写 AOP 拦截(自定义注解)的逻辑代码。
- 使用自定义注解。
具体实现如下。
添加 Spring AOP 依赖
在 pom.xml 中添加如下依赖:
<dependencies>
<!-- Spring AOP dependency -->
<dependency>
<groupIdorg.springframework.boot</groupId>
<artifactIdspring-boot-starter-aop</artifactId>
</dependency>
</dependencies>创建自定义注解
创建一个新的 Java 注解类,通过 @interface 关键字来定义,并可以添加元注解以及属性。
import java.lang.annotation.*;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CustomLogAnnotation {
String value() default "";
boolean enable() default true;
}在上面的例子中,我们定义了一个名为 CustomLogAnnotation 的注解,它有两个属性:value 和 enable,分别设置了默认值。
@Target(ElementType.METHOD) 指定了该注解只能应用于方法级别。
@Retention(RetentionPolicy.RUNTIME) 表示这个注解在运行时是可见的,这样 AOP 代理才能在运行时读取到这个注解。
编写 AOP 拦截(自定义注解)的逻辑代码
使用 Spring AOP 来拦截带有自定义注解的方法,并在其前后执行相应的逻辑。
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class CustomLogAspect {
@Around("@annotation(customLog)")
public Object logAround(ProceedingJoinPoint joinPoint, CustomLogAnnotation customLog) throws Throwable {
if (customLog.enable()) {
// 方法执行前的处理
System.out.println("Before method execution: " + joinPoint.getSignature().getName());
long start = System.currentTimeMillis();
// 执行目标方法
Object result = joinPoint.proceed();
// 方法执行后的处理
long elapsedTime = System.currentTimeMillis() - start;
System.out.println("After method execution (" + elapsedTime +
"ms): " + customLog.value());
return result;
} else {
return joinPoint.proceed();
}
}
}使用自定义注解
将自定义注解应用于需要进行日志记录的方法上,如下代码所示:
@RestController
public class MyController {
@CustomLogAnnotation(value = "This is a test method", enable = true)
@GetMapping("/test")
public String testMethod() {
// 业务逻辑代码
return "Hello from the annotated method!";
}
}实际工作中的注解
实际工作中我们通常会使用自定义注解来实现如权限验证,或者是幂等性判断等功能。
幂等性判断是指在分布式系统或并发环境中,对于同一操作的多次重复请求,系统的响应结果应该是一致的。简而言之,无论接收到多少次相同的请求,系统的行为和结果都应该是相同的。
如何实现自定义幂等性注解?
下面我们使用拦截器 + Redis 的方式来实现一下自定义幂等性注解,它的实现步骤如下:
- 创建自定义幂等性注解。
- 创建拦截器,实现幂等性逻辑判断。
- 配置拦截规则。
- 使用自定义幂等性注解。
具体实现如下。
创建自定义幂等性注解
@Retention(RetentionPolicy.RUNTIME) // 程序运行时有效
@Target(ElementType.METHOD) // 方法注解
public @interface Idempotent {
/**
* 请求标识符的参数名称,默认为"requestId"
*/
String requestId() default "requestId";
/**
* 幂等有效时长(单位:秒)
*/
int expireTime() default 60;
}创建拦截器
@Component
public class IdempotentInterceptor extends HandlerInterceptorAdapter {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
Method method = ((HandlerMethod) handler).getMethod();
Idempotent idempotent = method.getAnnotation(Idempotent.class);
if (idempotent != null) {
// 获取请求中的唯一标识符
String requestId = obtainRequestId(request, idempotent.requestId());
// 判断该请求是否已经处理过
if (redisTemplate.opsForValue().get(idempotentKey(requestId)) != null) {
// 已经处理过,返回幂等响应
response.getWriter().write("重复请求");
return false;
} else {
// 将请求标识符存入Redis,并设置过期时间
redisTemplate.opsForValue().set(idempotentKey(requestId), "processed", idempotent.expireTime(), TimeUnit.SECONDS);
return true; // 继续执行业务逻辑
}
}
return super.preHandle(request, response, handler);
}
private String idempotentKey(String requestId) {
return "idempotent:" + requestId;
}
private String obtainRequestId(HttpServletRequest request, String paramName) {
// 实现从请求中获取唯一标识符的方法
return request.getParameter(paramName);
}
}配置拦截器
在 Spring Boot 配置文件类中,添加拦截器配置:
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private IdempotentInterceptor idempotentInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(idempotentInterceptor)
.addPathPatterns("/**"); // 拦截所有接口
}
}使用自定义注解
最后,在需要进行幂等控制的 Controller 方法上使用 @Idempotent 注解:
@RestController
public class TestController {
@PostMapping("/order")
@Idempotent(requestId = "orderId") // 假设orderId是从客户端传来的唯一标识订单请求的参数
public String placeOrder(@RequestParam("orderId") String orderId, ...) {
// 业务处理逻辑
}
}这样,当有相同的请求 ID 在指定的有效期内再次发起请求时,会被拦截器识别并阻止其重复执行业务逻辑。
SpringBoot事务失效的场景有哪些?
一个程序中不可能没有事务,而 Spring 中,事务的实现方式分为两种:编程式事务和声明式事务,又因为编程式事务实现相对麻烦,而声明式事务实现极其简单,所以在日常项目中,我们都会使用声明式事务 @Transactional 来实现事务。
@Transactional 使用极其简单,只需要在类上或方法上添加 @Transactional 关键字,就可以实现事务的自动开启、提交或回滚了,它的基础用法如下:
@Transactional
@RequestMapping("/add")
public int add(UserInfo userInfo) {
int result = userService.add(userInfo);
return result;
}@Transactional 执行流程
@Transactional 会在方法执行前,会自动开启事务;在方法成功执行完,会自动提交事务;如果方法在执行期间,出现了异常,那么它会自动回滚事务。 然而,就是看起来极其简单的 @Transactional,却隐藏着一些“坑”,这些坑就是我们今天要讲的主题:导致 @Transactional 事务失效的常见场景有哪些?
在开始之前,我们先要明确一个定义,什么叫做“失效”?
本文中的“失效”指的是“失去(它的)功效”,也就是当 @Transactional 不符合我们预期的结果时,我们就可以说 @Transactional 失效了。
那 @Transactional 失效的场景有哪些呢?接下来我们一一来看。
非public修饰的方法
当 @Transactional 修饰的方法为非 public 时,事务就失效了,比如以下代码当遇到异常之后,不能自动实现回滚:
@Transactional
@RequestMapping("/save")
int save(UserInfo userInfo) {
// 非空效验
if (userInfo == null ||
!StringUtils.hasLength(userInfo.getUsername()) ||
!StringUtils.hasLength(userInfo.getPassword()))
return 0;
// 执行添加操作
int result = userService.save(userInfo);
System.out.println("add 受影响的行数:" + result);
int num = 10 / 0; // 此处设置一个异常
return result;
}以上程序的运行结果如下:
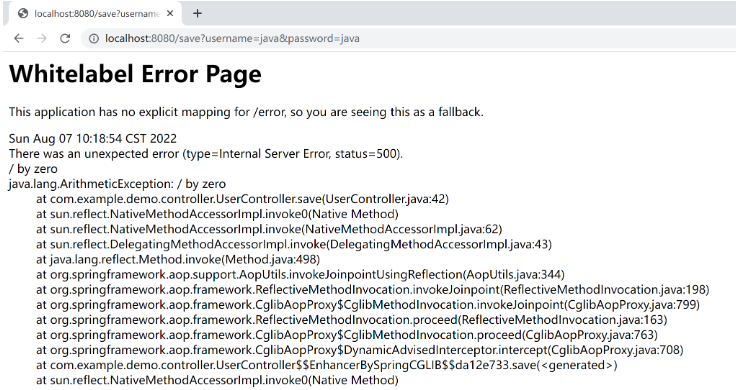
当程序出现运行时异常时,我们预期的结果是事务应该实现自动回滚,也就是添加用户失败,然而当我们查询数据库时,却发现事务并未执行回滚操作,数据库的数据如下图所示:

timeout超时
当在 @Transactional 上,设置了一个较小的超时时间时,如果方法本身的执行时间超过了设置的 timeout 超时时间,那么就会导致本来应该正常插入数据的方法执行失败,示例代码如下:
@Transactional(timeout = 3) // 超时时间为 3s
@RequestMapping("/save")
int save(UserInfo userInfo) throws InterruptedException {
// 非空效验
if (userInfo == null ||
!StringUtils.hasLength(userInfo.getUsername()) ||
!StringUtils.hasLength(userInfo.getPassword()))
return 0;
int result = userService.save(userInfo);
return result;
}UserService 的 save 方法实现如下:
public int save(UserInfo userInfo) throws InterruptedException {
// 休眠 5s
TimeUnit.SECONDS.sleep(5);
int result = userMapper.add(userInfo);
return result;
}数据库没有正确的插入数据
代码中有try/catch
在前面 @Transactional 的执行流程中,我们提到:当方法中出现了异常之后,事务会自动回滚。然而,如果在程序中加了 try/catch 之后,@Transactional 就不会自动回滚事务了,示例代码如下:
@Transactional
@RequestMapping("/save")
public int save(UserInfo userInfo) throws InterruptedException {
// 非空效验
if (userInfo == null ||
!StringUtils.hasLength(userInfo.getUsername()) ||
!StringUtils.hasLength(userInfo.getPassword()))
return 0;
int result = userService.save(userInfo);
try {
int num = 10 / 0; // 此处设置一个异常
} catch (Exception e) {
}
return result;
}
此时,查询数据库我们发现,程序并没有执行回滚操作,数据库中被成功的添加了一条数据,如下图所示:

调用类内部@Transactional方法
当调用类内部的 @Transactional 修饰的方法时,事务是不会生效的,示例代码如下:
@RequestMapping("/save")
public int saveMappping(UserInfo userInfo) {
return save(userInfo);
}
@Transactional
public int save(UserInfo userInfo) {
// 非空效验
if (userInfo == null ||
!StringUtils.hasLength(userInfo.getUsername()) ||
!StringUtils.hasLength(userInfo.getPassword()))
return 0;
int result = userService.save(userInfo);
int num = 10 / 0; // 此处设置一个异常
return result;
}以上代码我们在添加方法 save 中添加了 @Transactional 声明式事务,并且添加了异常代码,我们预期的结果是程序出现异常,事务进行自动回滚,以上程序的执行结果如下:
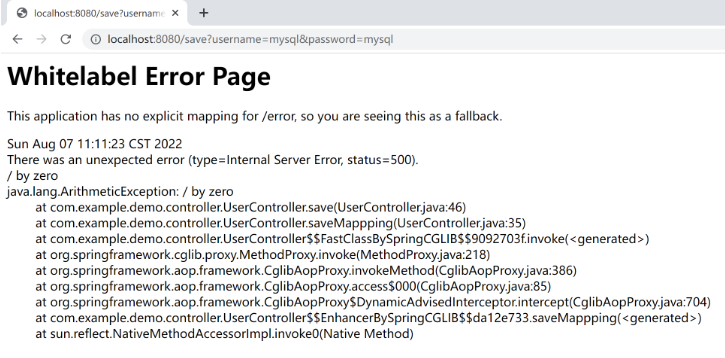
然而,当我们查询数据库时发现,程序执行并不符合我们的预期,添加的数据并没有进行自动回滚操作,如下图所示:
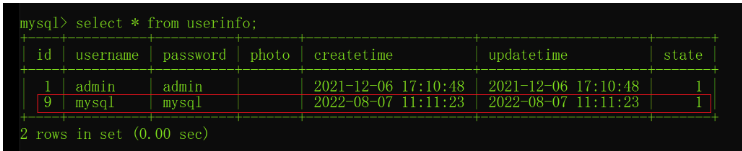
数据库不支持事务
我们程序中的 @Transactional 只是给调用的数据库发送了:开始事务、提交事务、回滚事务的指令,但是如果数据库本身不支持事务,比如 MySQL 中设置了使用 MyISAM 引擎,那么它本身是不支持事务的,这种情况下,即使在程序中添加了 @Transactional 注解,那么依然不会有事务的行为,这就是巧妇也难为无米之炊吧。
当声明式事务 @Transactional 遇到以下场景时,事务会失效:
- 非 public 修饰的方法;
- timeout 设置过小;
- 代码中使用 try/catch 处理异常;
- 调用类内部 @Transactional 方法;
- 数据库不支持事务。
什么是Spring事务传播机制?
Spring 事务传播机制是指在多个事务方法相互调用的情况下,如何管理这些事务的提交和回滚。
Spring 提供了七种事务传播行为,分别是:
- REQUIRED(默认传播行为):如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRESNEW:创建一个新的事务,如果当前存在事务,则挂起该事务。
- NOTSUPPORTED:以非事务方式执行操作,如果当前存在事务,则挂起该事务。
- NEVER:以非事务方式执行操作,如果当前存在事务,则抛出异常。
- NESTED:如果当前存在事务,则在嵌套事务中执行;如果当前没有事务,则创建一个新的事务。
Spring 提供了七种事务传播行为,可分为以下两类:
支持当前事务:
REQUIRED 是最常用的传播行为,它表示当前方法必须在一个事务内执行,如果当前没有事务,则创建一个新的事务。
SUPPORTS 表示当前方法支持事务,但不强制要求,如果当前没有事务,则以非事务方式执行。
MANDATORY 表示当前方法必须在一个事务内执行,如果当前没有事务,则抛出异常。
NESTED 表示当前方法必须在一个嵌套事务内执行,如果当前没有事务,则创建一个新的事务。
不支持当前事务:
REQUIRESNEW 表示当前方法必须创建一个新的事务,如果当前存在事务,则挂起该事务。
NOTSUPPORTED 表示当前方法以非事务方式执行,如果当前存在事务,则挂起该事务。NEVER 表示当前方法以非事务方式执行,如果当前存在事务,则抛出异常。
加入事务和嵌套事务有什么区别?
在 Spring 事务管理中,加入事务(Propagation.REQUIRED)和嵌套事务(Propagation.NESTED)是两种不同的事务传播行为。
- Propagation.REQUIRED:表示如果当前存在事务,则在当前事务中执行;如果当前没有事务,则创建一个新的事务并在其中执行。即,方法被调用时会尝试加入当前的事务,如果不存在事务,则创建一个新的事务。如果外部事务回滚,那么内部事务也会被回滚。
- Propagation.NESTED:表示如果当前存在事务,则在嵌套事务中执行;如果当前没有事务,则创建一个新的事务并在其中执行。嵌套事务是独立于外部事务的子事务,它具有自己的保存点,并且可以独立于外部事务进行回滚。如果嵌套事务发生异常并回滚,它将会回滚到自己的保存点,而不影响外部事务。
区别
Propagation.REQUIRED 是默认的传播行为,方法调用将加入当前事务,或者创建一个新事务。
Propagation.NESTED 是嵌套的传播行为,方法调用将在独立的子事务中执行,具有自己的保存点,可以独立于外部事务进行回滚,而不影响外部事务。
如果你希望内部方法能够独立于外部事务进行回滚,可以选择 Propagation.NESTED,如果你希望内部方法与外部事务一同回滚或提交,可以选择 Propagation.REQUIRED。
什么是跨域问题?如何解决?
跨域问题指的是不同站点之间,使用 ajax 无法相互调用的问题。跨域问题本质是浏览器的一种保护机制,它的初衷是为了保证用户的安全,防止恶意网站窃取数据。 但这个保护机制也带来了新的问题,它的问题是给不同站点之间的正常调用,也带来的阻碍,那怎么解决这个问题呢?接下来我们一起来看。
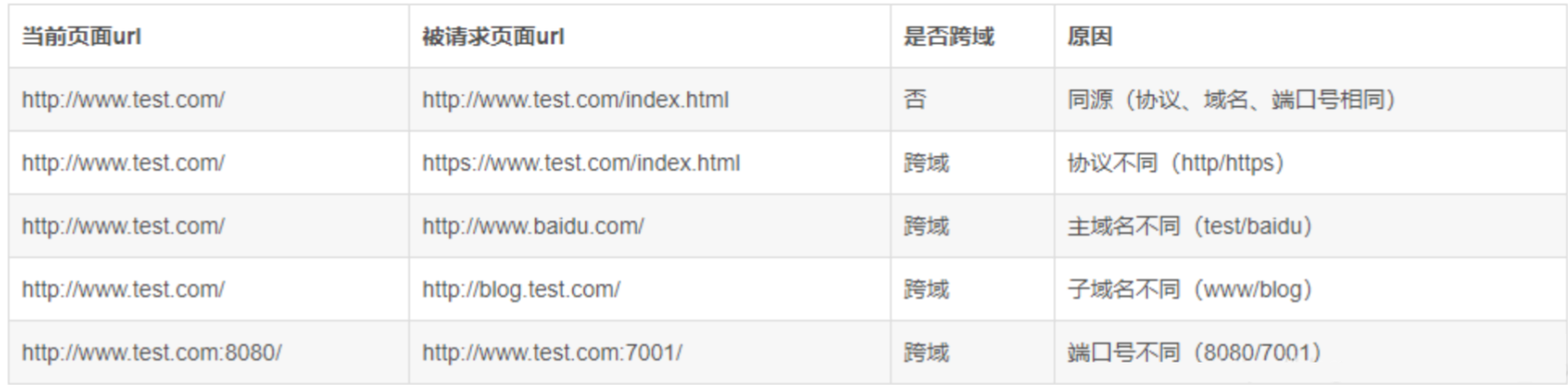
跨域三种情况
在请求时,如果出现了以下情况中的任意一种,那么它就是跨域请求:
- 协议不同,如 http 和 https;
- 域名不同;
- 端口不同。
也就是说,即使域名相同,如果一个使用的是 http,另一个使用的是 https,那么它们也属于跨域访问。
接下来,我们使用两个 Spring Boot 项目来演示跨域的问题,其中一个是端口号为 8080 的前端项目,另一个端口号为 9090 的后端接口项目。
前端项目只需要在 resources 下放两个文件,一个用于发送 ajax 请求的 jquery.js,另一个是 html 前端页面,工程目录如下图所示:
其中前端页面 index.html 的代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>跨域测试页面</title>
<script src="js/jquery.min.js"></script>
</head>
<body>
<h1>跨域测试</h1>
<div>
<input type="button" onclick="mySubmit()" value=" 发送跨域请求 ">
</div>
<script>
function mySubmit() {
// 发送跨域请求
jQuery.ajax({
url: "http://localhost:9090/test",
type: "POST",
data: {"name": "Java"},
success: function (result) {
alert("返回数据:" + result.data);
}
});
}
</script>
</body>
</html>后端接口项目首先先在 application.properties 配置文件中,设置项目的端口号为 9090,如下所示:
server.port=9090然后创建一个后端控制器,返回一个 JSON 格式的数据,实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
@RestController
public class TestController {
@RequestMapping("/test")
public HashMap<String, Object> test() {
return new HashMap<String, Object>() {{
put("state", 200);
put("data", "success");
put("msg", "");
}};
}
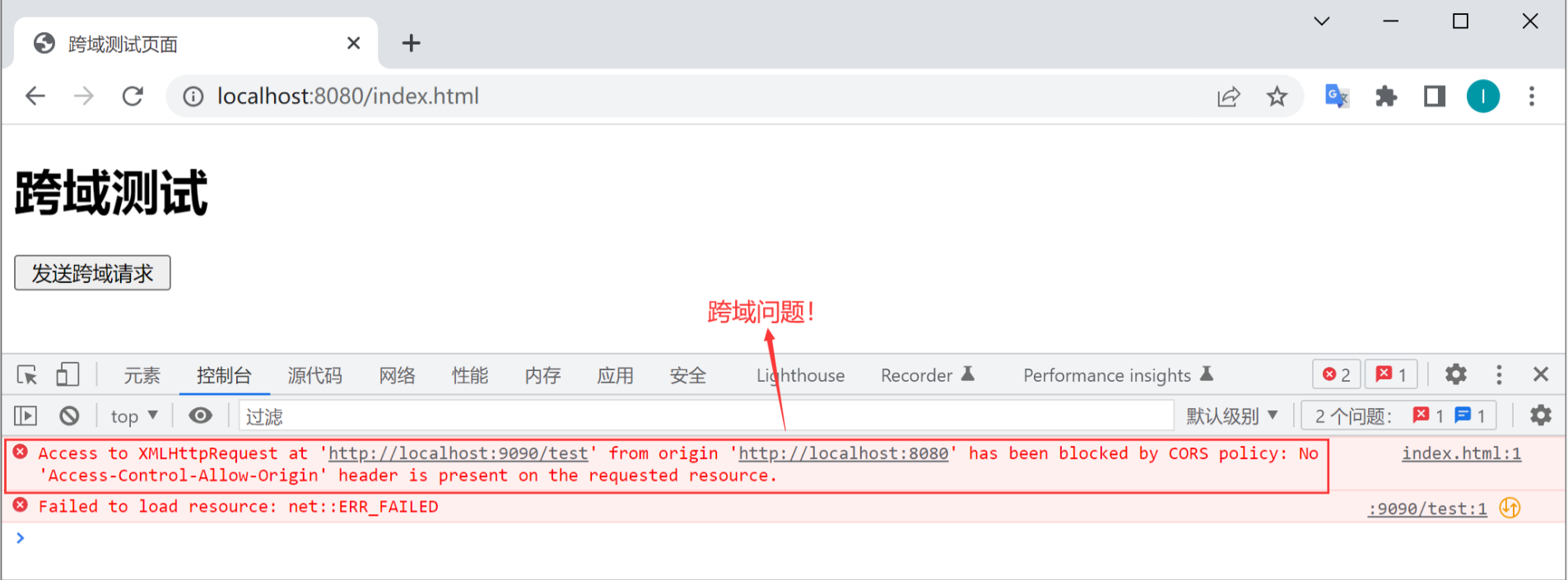
}以上两个项目创建并启动成功之后,使用前端项目访问后端接口,因为端口不一样,所以也属于跨域访问,运行结果如下图所示:
解决跨域问题
在 Spring Boot 中跨域问题有很多种解决方案,比如以下 5 个:
- 使用 @CrossOrigin 注解实现跨域;
- 通过配置文件实现跨域;
- 通过 CorsFilter 对象实现跨域;
- 通过 Response 对象实现跨域;
- 通过实现 ResponseBodyAdvice 实现跨域。
当然如果你愿意的话,还可以使用过滤器来实现跨域,但它的实现和第 5 种实现类似,所以本文就不赘述了。
通过注解跨域
使用 @CrossOrigin 注解可以轻松的实现跨域,此注解既可以修饰类,也可以修饰方法。当修饰类时,表示此类中的所有接口都可以跨域;当修饰方法时,表示此方法可以跨域,它的实现如下:
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
@RestController
@CrossOrigin(origins = "*")
public class TestController {
@RequestMapping("/test")
public HashMap<String, Object> test() {
return new HashMap<String, Object>() {{
put("state", 200);
put("data", "success");
put("msg", "");
}};
}
}以上代码的执行结果如下图所示:
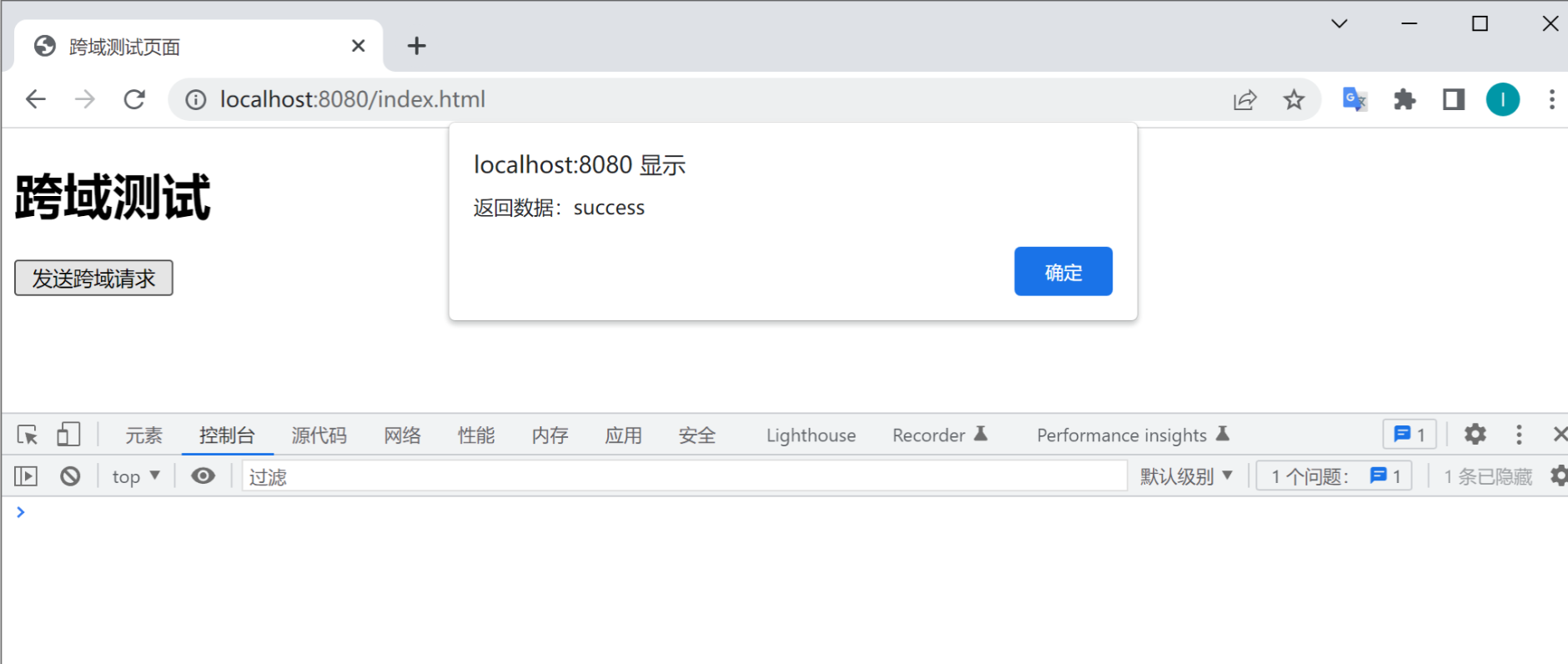
从上图中可以看出,前端项目访问另一个后端项目成功了,也就说明它解决了跨域问题。 优缺点分析 此方式虽然虽然实现(跨域)比较简单,但细心的朋友也能发现,使用此方式只能实现局部跨域,当一个项目中存在多个类的话,使用此方式就会比较麻烦(需要给所有类上都添加此注解)。
通过配置文件跨域
接下来我们通过设置配置文件的方式就可以实现全局跨域了,它的实现步骤如下:
- 创建一个新配置文件;
- 添加 @Configuration 注解,实现 WebMvcConfigurer 接口;
- 重写 addCorsMappings 方法,设置允许跨域的代码。
具体实现代码如下:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration // 一定不要忽略此注解
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**") // 所有接口
.allowCredentials(true) // 是否发送 Cookie
.allowedOriginPatterns("*") // 支持域
.allowedMethods(new String[]{"GET", "POST", "PUT", "DELETE"}) // 支持方法
.allowedHeaders("*")
.exposedHeaders("*");
}
}通过CorsFilter跨域
此实现方式和上一种实现方式类似,它也可以实现全局跨域,它的具体实现代码如下:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.UrlBasedCorsConfigurationSource;
import org.springframework.web.filter.CorsFilter;
@Configuration // 一定不能忽略此注解
public class MyCorsFilter {
@Bean
public CorsFilter corsFilter() {
// 1.创建 CORS 配置对象
CorsConfiguration config = new CorsConfiguration();
// 支持域
config.addAllowedOriginPattern("*");
// 是否发送 Cookie
config.setAllowCredentials(true);
// 支持请求方式
config.addAllowedMethod("*");
// 允许的原始请求头部信息
config.addAllowedHeader("*");
// 暴露的头部信息
config.addExposedHeader("*");
// 2.添加地址映射
UrlBasedCorsConfigurationSource corsConfigurationSource = new UrlBasedCorsConfigurationSource();
corsConfigurationSource.registerCorsConfiguration("/**", config);
// 3.返回 CorsFilter 对象
return new CorsFilter(corsConfigurationSource);
}
}通过Response跨域
此方式是解决跨域问题最原始的方式,但它可以支持任意的 Spring Boot 版本(早期的 Spring Boot 版本也是支持的)。但此方式也是局部跨域,它应用的范围最小,设置的是方法级别的跨域,它的具体实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.util.HashMap;
@RestController
public class TestController {
@RequestMapping("/test")
public HashMap<String, Object> test(HttpServletResponse response) {
// 设置跨域
response.setHeader("Access-Control-Allow-Origin", "*");
return new HashMap<String, Object>() {{
put("state", 200);
put("data", "success");
put("msg", "");
}};
}
}通过ResponseBodyAdvice跨域
通过重写 ResponseBodyAdvice 接口中的 beforeBodyWrite(返回之前重写)方法,我们可以对所有的接口进行跨域设置,它的具体实现代码如下:
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;
@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {
/**
* 内容是否需要重写(通过此方法可以选择性部分控制器和方法进行重写)
* 返回 true 表示重写
*/
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return true;
}
/**
* 方法返回之前调用此方法
*/
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType,
Class selectedConverterType, ServerHttpRequest request,
ServerHttpResponse response) {
// 设置跨域
response.getHeaders().set("Access-Control-Allow-Origin", "*");
return body;
}
}此实现方式也是全局跨域,它对整个项目中的所有接口有效。
为什么通过以上方法设置之后,就可以实现不同项目之间的正常交互呢? 这个问题的答案也很简单,我们之前在说跨域时讲到:“跨域问题本质是浏览器的行为,它的初衷是为了保证用户的访问安全,防止恶意网站窃取数据”,那想要解决跨域问题就变得很简单了,只需要告诉浏览器这是一个安全的请求,“我是自己人”就行了,那怎么告诉浏览器这是一个正常的请求呢?
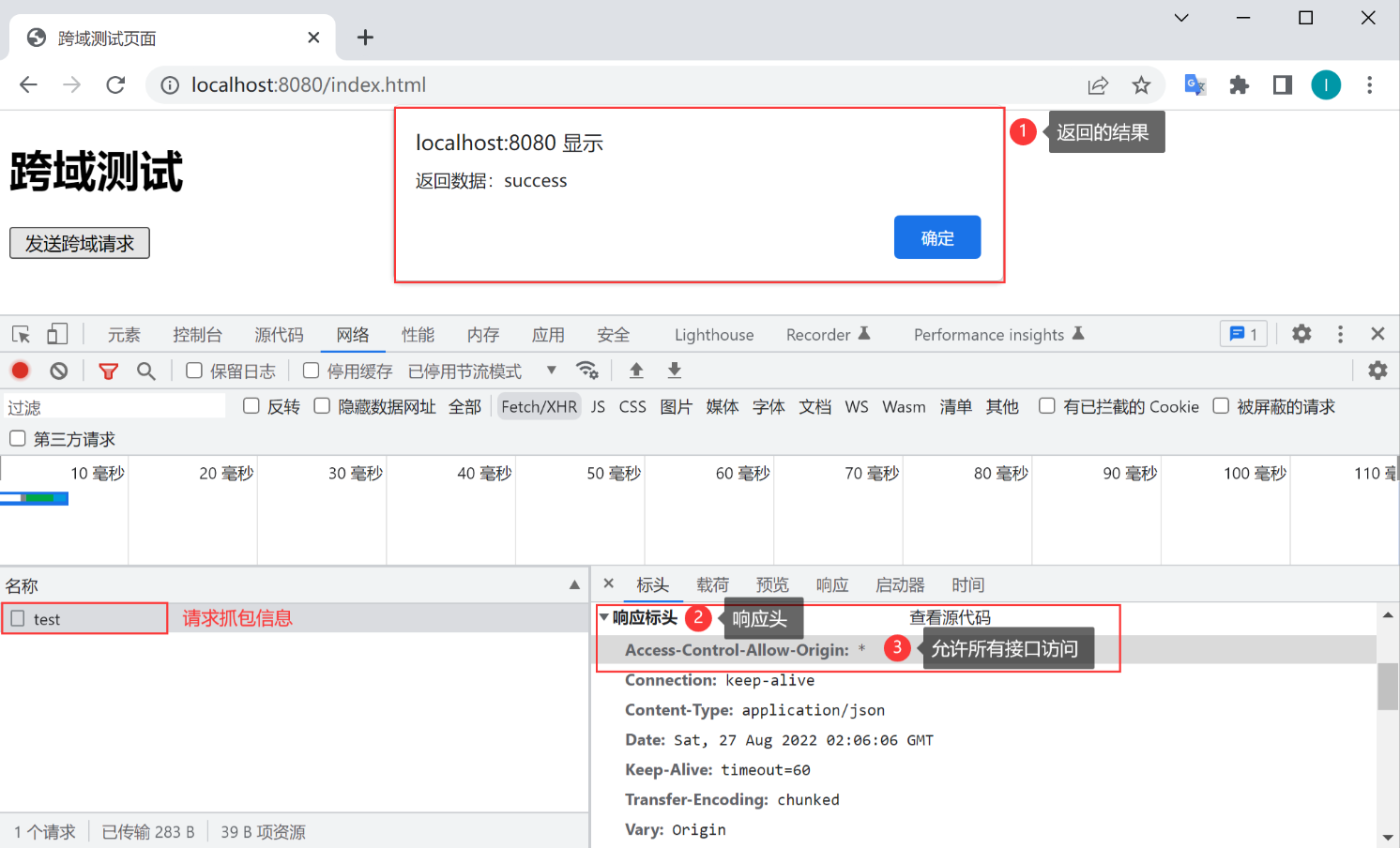
只需要在返回头中设置“Access-Control-Allow-Origin”参数即可解决跨域问题,此参数就是用来表示允许跨域访问的原始域名的,当设置为“*”时,表示允许所有站点跨域访问,如下图所示:
所以以上 5 种解决跨域问题的本质都是给响应头中加了一个 Access-Control-Allow-Origin 的响应头而已。
SpringBoot如何优雅停机?
优雅停机(Graceful Shutdown) 是指在服务器需要关闭或重启时,能够先处理完当前正在进行的请求,然后再停止服务的操作。
优雅停机的实现步骤主要分为以下几步:
- 停止接收新的请求:首先,系统会停止接受新的请求,这样就不会有新的任务被添加到任务队列中。
- 处理当前请求:系统会继续处理当前已经在处理中的请求,确保这些请求能够正常完成。这通常涉及到等待正在执行的任务完成,如处理HTTP请求、数据库操作等。
- 释放资源:在请求处理完成后,系统会释放所有已分配的资源,如关闭数据库连接、断开网络连接等。
- 关闭服务:最后,当所有请求都处理完毕且资源都已释放后,系统会安全地关闭服务。
如何优雅停机
优雅停机的实现步骤分为以下两步:
- 使用合理的 kill 命令,给 Spring Boot 项目发送优雅停机指令。
- 开启 Spring Boot 优雅停机/自定义 Spring Boot 优雅停机的实现。
在 Linux 中 kill 杀死进程的常用命令有以下这些:
- kill -2 pid:向指定 pid 发送 SIGINT 中断信号,等同于 ctrl+c。也就说,不仅当前进程会收到该信号,而且它的子进程也会收到终止的命令。
- kill -9 pid:向指定 pid 发送 SIGKILL 立即终止信号。程序不能捕获该信号,最粗暴最快速结束程序的方法。
- kill -15 pid:向指定 pid 发送 SIGTERM 终止信号。信号会被当前进程接收到,但它的子进程不会收到,如果当前进程被 kill 掉,它的的子进程的父进程将变成 init 进程 (init 进程是那个 pid 为 1 的进程)。
- kill pid:等同于 kill 15 pid。
因此,在以上命令中,我们不能使用“kill -9”来杀死进程,使用“kill”杀死进程即可。
在 Spring Boot 2.3.0 之后,可以通过配置设置开启 Spring Boot 的优雅停机功能,如下所示:
# 开启优雅停机,默认值:immediate 为立即关闭
server.shutdown=graceful
# 设置缓冲期,最大等待时间,默认:30秒
spring.lifecycle.timeout-per-shutdown-phase=60s此时,应用在关闭时,Web 服务器将不再接受新请求,并等待正在进行的请求完成的缓冲时间。
然而,如果是 Spring Boot 2.3.0 之前,就需要自行扩展(线程池)来实现优雅停机了。它的核心实现实现是在系统关闭时会调用 ShutdownHook,然后在 ShutdownHook 中阻塞 Web 容器的线程池,直到所有请求都处理完毕再关闭程序,这样就实现自定义优雅线下了。
但是,不同的 Web 容器(Tomcat、Jetty、Undertow)有不同的自定义优雅停机的方法,以 Tomcat 为例,它的自定义优雅停机实现如下。
Tomcat容器关闭代码
public class TomcatGracefulShutdown implements TomcatConnectorCustomizer, ApplicationListener<ContextClosedEvent> {
private volatile Connector connector;
public void customize(Connector connector) {
this.connector = connector;
}
public void onApplicationEvent(ContextClosedEvent contextClosedEvent) {
this.connector.pause();
Executor executor = this.connector.getProtocolHandler().getExecutor();
if (executor instanceof ThreadPoolExecutor) {
try {
log.info("Start to shutdown tomcat thread pool");
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
threadPoolExecutor.shutdown();
if (!threadPoolExecutor.awaitTermination(20, TimeUnit.SECONDS)) {
log.warn("Tomcat thread pool did not shutdown gracefully within 20 seconds. ");
}
} catch (InterruptedException e) {
log.warn("Fail to shut down tomcat thread pool ", e);
}
}
}
}设置自动装配
设置 Tomcat 自动装配@Configuration
@ConditionalOnClass({Servlet.class, Tomcat.class})
public static class TomcatConfiguration {
@Bean
public TomcatGracefulShutdown tomcatGracefulShutdown() {
return new TomcatGracefulShutdown();
}
@Bean
public EmbeddedServletContainerFactory tomcatEmbeddedServletContainerFactory(TomcatGracefulShutdown gracefulShutdown) {
TomcatEmbeddedServletContainerFactory tomcatFactory = new TomcatEmbeddedServletContainerFactory();
tomcatFactory.addConnectorCustomizers(gracefulShutdown);
return tomcatFactory;
}
}